
讯飞AI 大学堂
AI University is an online AI learning platform developed by iFlytek, offering a wealth of courses and practical opportunities to help developers and enthusiasts enhance their AI skills.
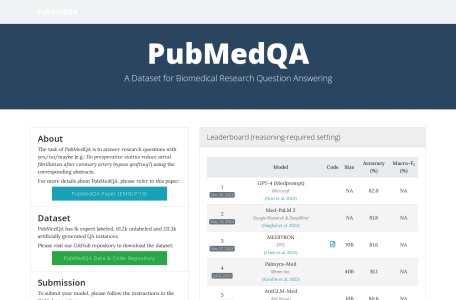
PubMedQA is a question-answering dataset tailored for the biomedical field, comprising 1,000 expert-labeled, 61,200 unlabeled, and 211,300 artificially generated QA insta...
In today’s era of information explosion, obtaining accurate answers to medical research questions is crucial for researchers and clinicians. PubMedQA is a biomedical research question-answering dataset designed to enhance the accuracy and efficiency of medical QA through AI technology.
PubMedQA focuses on question-answering tasks in the biomedical field, providing a large dataset for researchers to train and evaluate AI models.
The PubMedQA dataset has been utilized by numerous renowned AI research institutions for model training and evaluation, promoting advancements in the biomedical QA field.
The PubMedQA dataset is completely free, available for download from its GitHub repository.
PubMedQA was released in 2019 by research teams from the University of Pittsburgh and Carnegie Mellon University, aiming to provide high-quality data support for AI research in the biomedical field. Through this dataset, researchers can train and evaluate models to improve the accuracy and efficiency of medical question-answering.